Theories on transformer function
Theories on transformer function
Transformers are SVMs
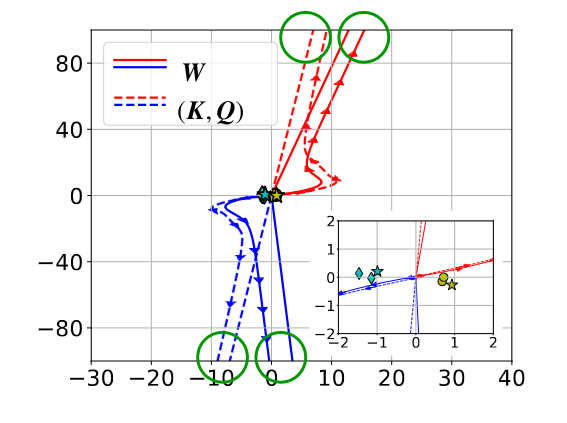
I recently saw a new paper called “Transformers are Support Vector Machines” which I thought was very interesting. The authors describe a way to interpret the attention mechanism, a key component of transformers that can be difficult to interpret. The idea is that the action of attention parameterizes an SVM at every layer, which the function of learning to separate (or give very small or zero softmax weight) to the irrelevant parts of the input. This comes in the form of maximizing the distance between sets of tokens (the “good” ones and the “bad” ones), as in the below figure, where the lines illustrate the different trajectories of two token sets (presumably, the red lines refer to the “good” tokens) and the inset shows with stars the “optimal” SVM-solution tokens.
Transformers are coding rate reducers
The idea of creating separability or “distance” between related samples in some arbitrary data matrix reminds me of the principle of rate reduction, as defined in the papers “White-box transformers via sparse rate-reduction and “Learning diverse and discriminative representations via the principle of maximal coding rate reduction”. This second work establishes three basic principles for desirable neural representations:
- between-class discriminative: features from different classes should end up in different low-dim and hopefully linear subspaces
- within-class compressible: features from similar classes should end up in similar low-dimensional subspaces (i.e. the subspaces should be “close” to each other)
- maximially diverse representation: the overall variance of each class should be as large as possible (intuitively this is meant to prevent feature collapse, where for example a class could be mapped to a singular vector or an inappropriately low-rank subspace as can happen in some algorithms)
What this looks like is something like this:
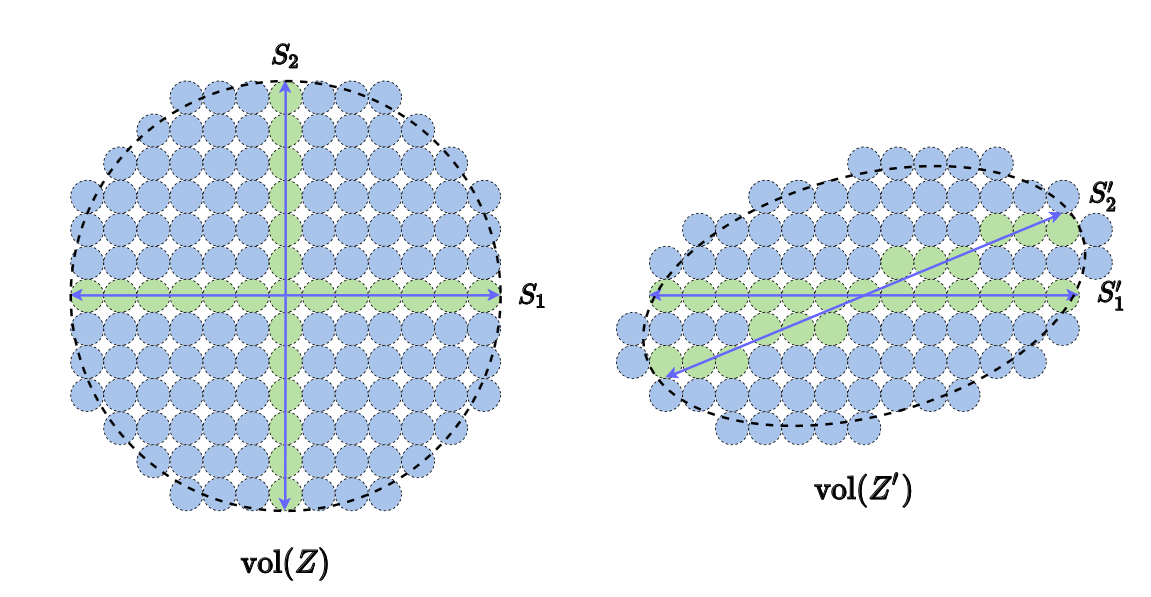
And the idea is to use as a way to quantify the “volume” of a data matrix. If is a subspace with correlated features, then will be small (left of figure). If is a subspace with uncorrelated features, then will be large (right of figure). The goal of representation learning might then be posed as a way to discover a feature transformation such that the overall volume of the data matrix is maximized, but where there is high separability and low coherence between the features for each class-specific subspace.
A recent investigation into transformers extends some of this theory to t ransformers, establishing a class of models which interprets the two building blocks of the self-attention layer from this perspective. Self-attention operations are viewed as incremental rate-reduction compression operations. The MLP operations are then interpreted as ISTA-like operations (shrinkage/sparsifying operations) that sparsify the token features with respect to some global basis functions (referred to as a global dictionary). This class of methods is then referred to as CRATE, or Coding Rate Transformer. The performance of these models is not quite as good as, for example, ViT, but the authors suggest that the benefits of interpretability are worth the trade-off and that a number of innovations have gone into training ViT and ViT-like models.